BigData
Modèles de calcul du Big Data
Description : Ce cours a pour objectif d’apprendre aux élèves à développer des applications performantes d’analyse de données en environnement Spark sur des plates-formes distribuées (clusters et Clouds). Des mécanismes de systèmes de fichiers distribués comme HDFS seront étudiés, ainsi que le modèle de programmation et l’algorithmique du “map-reduce étendu” de Spark au dessus des Spark “RDD”, puis des modèles de programmation de plus haut niveau au dessus de Spark “Data Frames”, et enfin des modèles de programmation sur Cloud. Des critères et métriques de passage à l’échelle seront également étudiés. Tout au long du cours des mises en oeuvres auront lieu sur des clusters et dans un Cloud, et les solutions développées seront évaluées par les performances obtenues sur les cas-tests, et par leur aptitude à passer à l’échelle.
Contenu : Emergence des technologies Big Data : motivations, besoins industriels, principaux acteurs. Pile logicielle d’Hadoop, architecture et fonctionnement de son système de fichier distribué (HDFS) Architecture et mécanisme de déploiement de calculs distribués de Spark Modèle de programmation par “RDD” et algorithmique du “map-reduce” étendu de Spark Modèle de programmation de Spark par “Data Frames” appliqué à l’analyse de graphes (GraphX) Architecture et environnement d’analyse de données sur Cloud Expérimentations et mesures de performances Critères et métriques de performances
Acquis d’apprentissage : A l’issue de ce cours, les élèves seront en mesure :
AA1 : de concevoir et d'implanter des algorithmes "map-reduce étendu" en Spark, efficaces sur des plates-formes distribuées, et passant à l'échelle.
AA2 : d'analyser les capacités de "passage à l'échelle" d'une application
AA3 : d'utiliser un cluster ou un cloud pour réaliser des analyses de données distribuées à large échelle.
AA4 : de présenter synthétiquement une solution d'analyse de données conçue en "map-reduce"
Méthodes pédagogiques : Ce cours enchaîne 3 parties relatives à des modèles de calculs du “Big Data” : la première sur clusters de PC, la seconde dans les Cloud, et la troisième qui évalue des solutions de “passage à l’échelle”.
Plan du cours en 4 parties :
Partie 1 : Architecture et développement en Spark RDD sur HDFS et clusters de PC.
Partie 2 : Critères et métriques pour la performance et le passage à l'échelle.
Partie 3 : Calcul et analyse de données large échelle sur Cloud.
Partie 4 : Développement en Spark Data Frames sur HDFS et clusters de PC.
Moyens : Equipe enseignante : Stéphane Vialle et Gianluca Quercini (CentraleSupelec), Wilfried Kirschenmann (ANEO) Plateforme de développement et d’exécution : clusters de calcul du Data Center d’Enseignement (DCE) du campus de Metz de CentraleSupélec accès à un Cloud professionnel Environnements de développement : Spark + HDFS sur le DCE autre environnement sur le Cloud
Modalités d’évaluation : Evaluation à partir des TP :
Les comptes rendus des TP seront notés (le contenu et le nombre de pages des comptes rendus sont contraints, afin de forcer les étudiants à un effort de synthèse et de clarté)
En cas d'absence non justifié à un TP la note de 0 sera appliquée, en cas d'absence justifiée le TP n'interviendra pas dans la note finale.
L'examen de rattrapage sera un examen oral, qui constituera 100% de la note de rattrapage.
Compétences évaluées :
- Être opérationnel, responsable et innovant dans le monde numérique
- Savoir convaincre
Responsable de cours : Stéphane Vialle
Identifiant Geode : 3MD4130
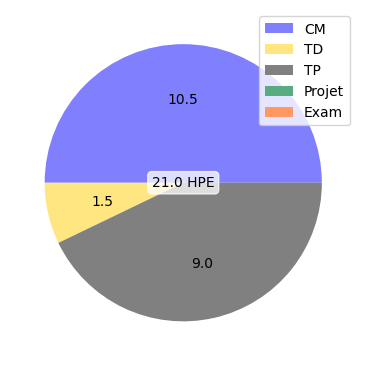
CM :
- Emergence du Big Data et technologie HDFS d’Hadoop (1.5 h)
- Technologie Spark-RDD et programmation Map-Reduce (1.5 h)
- Optimisation et déploiement de codes Map-Reduce (1.5 h)
- Métriques de passage à l’échelle et architecture des Data Lakes (1.5 h)
- Spark Data-Frames et Spark SQL (1.5 h)
- Problématiques du cloud (1.5 h)
- Environnement de développement sur cloud (1.5 h)
TD :
- Algorithmique Map-Reduce en Spark (1.5 h)
TP :
- Map-Reduce sur cluster Spark-HDFS: programmation et performances (3.0 h)
- Analyse de données en Spark Data-Frame et Spark SQL sur cluster Spark-HDFS (3.0 h)
- Développement et déploiement d’une analyse de données extensible sur Cloud (3.0 h)