ModStat1
Modèles statistique 1
Description : Les cours “Modélisation statistique” ModStat1 et ModStat2 traitent de la modélisation de systèmes pour lesquels les sorties sont suffisamment incertaines pour qu’elles nécessitent d’être modélisées par des variables aléatoires. Le cours débute avec des rappels en statistique et l’introduction de modèles élémentaires (e.g. naive Bayes, régression linéaire, etc) pour aller progressivement vers des modèles plus complexes. Si les cours présentent les modèles et méthodes élémentaires les plus utiles dans ce contexte de modélisation, ils ne se veulent pas être un catalogue exhaustif. L’objectif est davantage de présenter au sein d’une théorie cohérente les concepts et outils théoriques communs à l’ensemble de ces modèles et méthodes et de montrer comment à partir d’hypothèses de modélisation propres à chaque problème concret, ces concepts sont assemblés logiquement avant d’aboutir à une méthode opérationnelle. D’un point de vue pratique l’enjeu de ce cours est non seulement de donner aux étudiants les moyens de comprendre et d’utiliser à bon escient les implémentations existantes de modèles mais aussi de concevoir ses propres implémentations pour prendre en compte les particularités d’un problème donné. Le cours s’attache à rattacher la théorie à la pratique : sont d’abord identifiées en cours les hypothèses associées à une classe de problèmes donnée, s’ensuit un travail théorique de modélisation, qui conduit à définir un modèle et ses algorithmes d’estimation. Ces résultats sont alors appliqués à un cas d’étude en TD avant de faire l’objet en TP d’un travail d’implémentation (en Python) et d’évaluation sur des données. Le cours ModStat1 introduira les outils de bases de la modélisation statistique quand le cours ModStat2 se concentrera sur les modèles à variables cachées.
Prérequis :
- Connaissances de base en théorie des probabilités, statistique et apprentissage machine (machine learning)
- Niveau débutant en programmation Python / Numpy
Acquis d’apprentissage :
- Être capable de choisir un modèle/ une méthode statistique adaptée au problème considéré et de la mettre en œuvre de façon appropriée.
- Être capable de comprendre les concepts théoriques sous-jacents à une méthode d’inférence statistique présentée dans un article scientifique.
- Être capable d’implémenter un modèle / une méthode statistique dans un langage tel que Python.
- Être capable d’adapter un modèle / une méthode pour tenir compte des spécificités du problème traité.
Modalités d’évaluation : Examen écrit de 2h sans documents, rattrapable.
Compétences évaluées :
- Analyser, concevoir et réaliser des systèmes complexes
- Développer ses compétences dans un domaine d’ingénieur et dans un métiers
Responsable de cours : Frédéric Pennerath
Identifiant Geode : 3MD1530
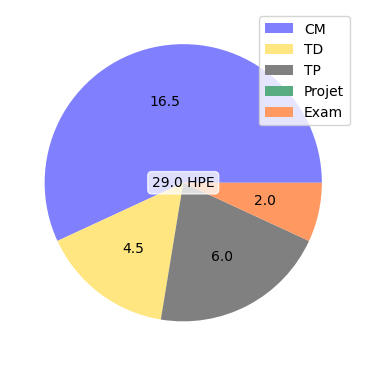
CM :
- Modèles statistiques (1.5 h)
- Estimation (1.5 h)
- Estimation bayésienne (1.5 h)
- Réseaux bayésiens 1 (1.5 h)
- Naive Bayes (1.5 h)
- Réseaux bayésiens 2 (1.5 h)
- Causalité (1.5 h)
- Modèles gaussiens (1.5 h)
- Modèles linéaires (1.5 h)
- Famille exponentielle (1.5 h)
- GLM (1.5 h)
TD :
- Estimation bayésienne (1.5 h)
- Modélisation causale (1.5 h)
- Régression (1.5 h)
TP :
- Modélisation et modèles gaussiens (3.0 h)
- Régression (3.0 h)